Jos
libLISA - Instruction Discovery and Analysis on x86-64
In order to understand raw machine code instructions in a binary program, we need descriptions of what instructions do: instruction semantics. Every tool (or human) operating on binaries uses these: from disassemblers and decompilers, to static binary analysis, dynamic instrumentation or emulation.
It is important that instruction semantics are correct. Errors in instruction semantics propagate to the final output of a binary analyzer or emulator, making them behave incorrectly. Differences between actual CPU behavior and these tools pose a security risk: malware can abuse such differences to obfuscate its behavior, or evade analysis in controlled environments like emulators.
To make matters more complicated, on the x86 architecture there is no single correct semantics for some instructions: "undefined behavior" allows instructions to behave differently on different CPUs.
libLISA is a tool that can fully automatically scan instruction space, discover instructions and synthesize their semantics. It produces machine-readable, CPU-specific x86-64 instruction semantics. It relies on as little human specification as possible: specifically, it does not rely on a handwritten (dis)assembler to dictate which instructions are executable on a given CPU, or what their operands are.
The semantics generated by libLISA model real CPU behavior, including undefined behavior. We can use these semantics to find differences between architectures, verify that other semantics are correct, or even generate CPU-specific (userspace) emulators automatically.
My current focus is on using libLISA's automatically inferred semantics to verify the correctness of disassemblers, emulators and other semantics.
Sem86: A full-system emulator without hard-coded semantics
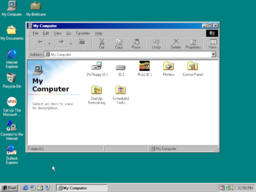
No two x86 CPUs are identical: undefined behavior differs in every CPU generation. Existing emulators contain hard-coded semantics, making it impossible to easily switch between different behavior. Sem86, instead, loads its semantics at runtime from data in an input file.
All necessary hardware needed to emulate typical x86 operating systems such as Windows 98, Windows XP and Windows 7, is implemented. A sound card, network card and high-resolution display output are also implemented.
Sem86 can automatically bisect instruction execution to determine at which point different semantics would diverge. We demonstrate this by constructing a toy malware example that exploits undefined instruction behavior to detect whether it is running in an emulator. Sem86 can pinpoint the exact instruction that is used to do this.
The long-term goal for Sem86 is to integrate semantics automatically derived with libLISA. Currently, Sem86 uses handwritten instruction semantics. This is because libLISA currently does not have CPU observers for 16-bit and 32-bit x86, and therefore does not have inferred semantics available. However, the semantics format that we use is very similar to libLISA's, and switching to automatically inferred semantics would not require big changes.